一花一世界,一树一菩提:编码压缩探索与实践
前言
你可曾面临这种问题,高并发条件下数据必须99%cache命中才能满足性能需求?
你可曾面对这种场景,对cache集群不断扩容是否让你感到厌烦?
那么是否有一种办法在提高缓存命中率的同时,又能提高缓存集群键个数,甚至于提高整个集群的吞吐?
本文将从实践出发,对编码方式及压缩算法进行介绍,并分享了在真实项目中使用缓存压缩对性能的影响。
探索篇
提高缓存命中率有很多种方法:选择好的缓存淘汰算法。固然有一些本地缓存支持LFU或者更新的Tiny LFU算法。不过对于分布式缓存而言,memcached和redis底层都使用了LRU算法,并不支持淘汰算法的替换。
由此,我们想到第二个思路:提升集群item数量。
在不扩容、不拆分item的前提下,便理所应当的想到了对item进行压缩存储。
那么接下来需要确定的就是具体的压缩方案:即对何种数据进行压缩才是最有效的?采用何种压缩算法才是最适合我们的系统的?
编码方式
不同的压缩算法之间区别最大的即在于编码方式。所谓编码其本质即把信息进行某种方式的转换,以便让信息能够装载进目标载体。从信息论的角度来说,编码的本意并非改变信息的熵密度,而只是改变信息的表现形式。
游程编码:最易理解的编码方式
该算法的实现是用当前数据元素以及该元素连续出现的次数来取代字符串中连续出现的数据部分。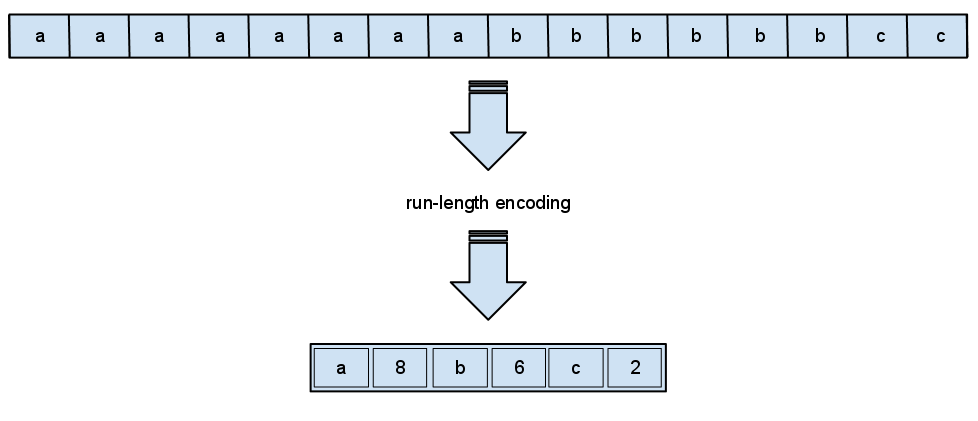
aaaaaaaaaabbbaxxxxyyyzyx
字符串长度为24,使用游程算法,我们用较短的字符串后加一个计数值来替换游程对象。
a10b3a1x4y3z1y1x1
通过游程编码编码后的字符串长度为17,只有原先的71%,但仍有优化的余地,比如对于只出现一次的字符,不在后面追加1.
a10b3ax4y3zyx
这样编码得来的字符串只有13,只有原先的51%
熵编码
熵编码被人所熟知的一种即是Huffman编码,它的原理是根据字符在原始串中出现的概率。通过构造一颗二叉树来为每个字符产生对应的码字,又称最佳编码。
算术编码
算术编码同样是一种熵编码,它同样是基于字符在原始串中出现的概率。所不同的是Huffman编码对每个字符产生码字。而算术编码通常将原始串编码为一个介于0~1之间的小数。
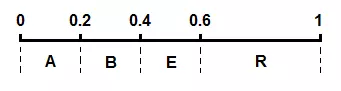
比如说对于原始串ARBER,我们得出每个字符出现的概率表:
| Symbol | Times | P | Interval |
|---|---|---|---|
| A | 1 | 0.2 | 0 - 0.2 |
| B | 1 | 0.2 | 0.2 - 0.4 |
| E | 1 | 0.2 | 0.4 - 0.6 |
| R | 2 | 0.4 | 0.6 - 1.0 |
通过这张概率表,我们可以将0~1这个区间按照概率划分给不同的字符。
编码器将当前的区间分成若干子区间,每个子区间的长度与当前上下文下可能出现的对应符号的概率成正比。当前要编码的符号对应的子区间成为在下一步编码中的初始区间。
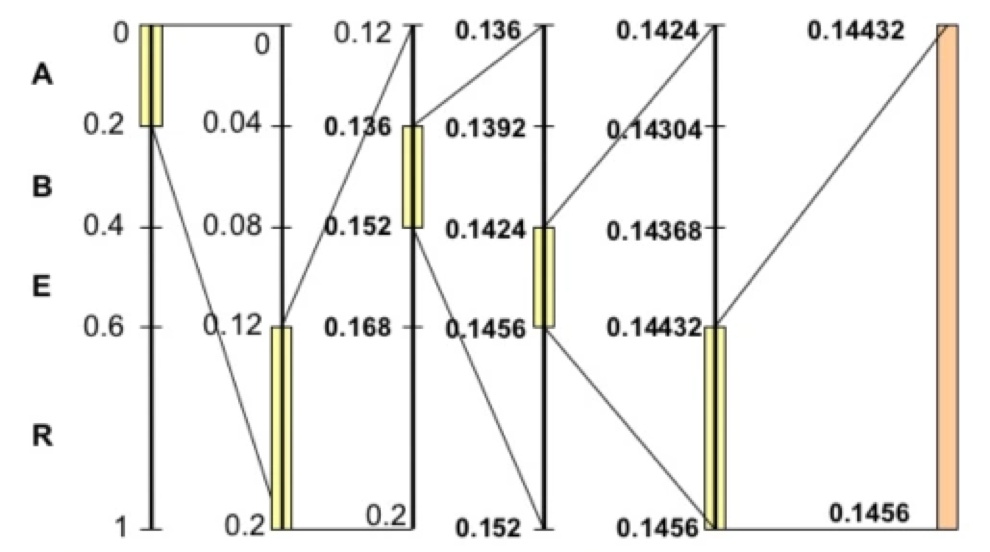
以ARBER为例,由上图可以得到以下类推流:
A的区间是(0,0.2),这个区间成为下一步编码的初始区间。R的区间是(0.6,1.0),那么在初始区间(0,0.2)中取相对的(0,6,1.0)区间即(0,12,0.2)做这一步编码结果,也即是下一步编码的子区间。以此类推,最终得到了(0.14432,0.14456)作为结果区间。
这里我们只是介绍算术编码的思想,使用十进制也是为了方便理解。在实际算法实现中,概率以及区间的表示都是使用二进制的小数去表示。很可能不是一精确的小数值,这一定程度上也会影响算法的编码效率。
从实用效果上,算术编码的压缩比一般要好于Huffman。但Huffman的性能要优于算术编码,两者都有自适应的算法,不必依赖全文进行概率统计,但毕竟算术编码还是需要更大的计算量。
字典编码
字典编码是指用符号代替一串字符,在编码中仅仅把字符串看成是一个号码,而不去管它来表示什么意义。
LZ77编码
LZ77是Abraham Lempel与Jacob Ziv在1977年以及1978年发表的论文中的一种无损压缩编码。
它通过使用编码器或者解码器中已经出现过的相应匹配数据信息替换当前数据从而实现压缩功能。这个匹配信息使用称为长度-距离对的一对数据进行编码。
编码器和解码器都必须保存一定数量的最近的数据,如最近2 KB、4 KB或者32 KB的数据。保存这些数据的结构叫作滑动窗口,因为这样所以LZ77有时也称作滑动窗口压缩。
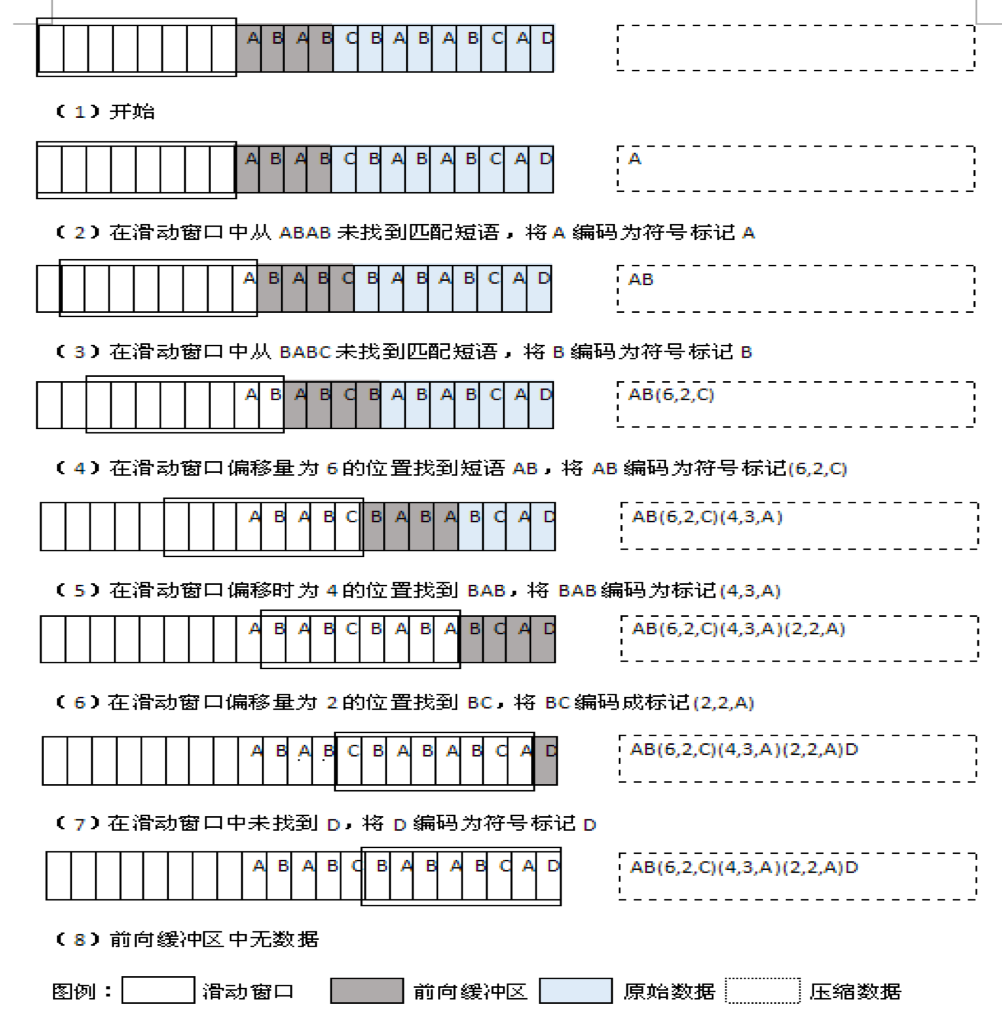
关于LZ77编码,还有一点需要了解的是它如何表示被压缩数据。它并非是对单个字符进行编码,而是对匹配的字符串进行编码。形式为(p,l,c).p表示匹配在滑动窗口的相对起始下标,l表示匹配到滑动窗口的字符串的长度,c表示第一个未匹配的字符。
拿ABABCBABABCAC举例,使用长度为8byte的滑动窗口,长度为4byte的前向缓冲区。
ANS编码
ANS是前两类编码算法战争的终结者。它在2014年被提出来,随后很快就得到了大量应用。本质上属于算术编码,但它成功地找到了一个用近似概率表示的表格,将原来的概率计算转换为查表。所以它是一个达到Huffman编码效率的算术编码方法。FSE(Finite State Entropy)是ANS最为著名的实现。
实际上,大多数压缩算法的实现往往不会只基于一种特定的编码方式,而是将多种编码方式组合起来使用。关于压缩算法和编码方式的关系,可以简单将其考虑成排序算法和各种实现类比起来。
无损压缩算法实现
压缩算法可以按照特定的编码机制用比未经编码少的数据位元(或者其它信息相关的单位)表示信息。以下所讨论的压缩算法都是无损压缩算法,本质并不会减少信息熵。
不同的压缩算法针对不同的测试集,在压缩比和吞吐率方向上有不同的变相。为了尽可能减小这种不同测试集带来的误差。Silesia压缩语料库提供了text, exe, pdf, html等常见的格式内容。因此,诸多的压缩算法都将Silesia语料库作为测试基准来测试其性能。
但需要注意的是:通用的标准并不一定适合你的数据。一定要根据自己的数据进行实测后选择压缩算法。
Deflate
Deflate基于LZ77和Huffman编码方式的变形,因为历史原因,在很多地方得到了应用,比如zip,Gzip,png等处。
Gzip
一种广为人知的压缩算法。其提供了不同的压缩级别,使用压缩比来交换吞吐率。但一般来说,Gzip的压缩比较高,响应的吞吐率较差。我们知道在http中,Accept-Encoding常常选择使用Gzip用来提高传输效率。
LZ4
lz4最大特点是其吞吐率特别高,提供了单核500MB/s的压缩速度,解压速度更是上GB/s,已经基本达到了多核系统的内存速度的上限。
Snappy
Google在2011年开源的通用压缩算法,使用C++实现。号称注重吞吐率但实际上跟lz4还有较大的差距。官方的意思大概是相比于Gzip有很大提升。
Zstandard
![]()
Facebook推出的实时压缩算法,全称为Zstandard,使用C实现,基于FSE熵编码。最大的特点是对小数据使用了“字典训练”的模式,在使用字典的条件下,其压缩比和吞吐率会有很大幅度的提高。它同样提供了22种压缩级别,官方默认的压缩级别为3,但实测在最低压缩级别下,其表现已经十分优秀。
Brotli

Google出品的另一种压缩算法实现,基于通用的LZ77和Huffman编码,其比较特殊的地方是使用了二阶上下文建模,可以简单理解为根据上下文去判断下一个字符出现的概率从而实现压缩。在速度下和Deflate很接近,但却提供了更高的压缩比。目前主要的应用方向应该是web内容的压缩。
另一个主要的特点的是brotli内置了常用词的字典,已被证明可以增加压缩比。
实践篇
本次实践的对象是约1.1KB的pb字节对象。系统原先的存储方式是Java pojo类转为pb对象再转为pb字节对象存至memcached,读写比为35.这样一种场景其实也符合大部分互联网公司的实际业务场景,读多写少,开发人员更关心读的吞吐和CPU的占用率。
因此,所使用的性能测试方案分为两步:在本地使用jmh测试诸多压缩算法的压缩比和吞吐率;线上使用memcached测试集群mock大量读请求,测试CPU占用和吞吐。
压缩比
| Method | maxRatio | minRatio | averageRatio |
|---|---|---|---|
| 使用zstd进行压缩 | 2.43 | 1.19 | 1.72 |
| 使用同组数据训练得到的dict进行zstd压缩 | 7.22 | 1.87 | 4.58 |
| 使用不同组数据训练得到的dict进行zstd压缩 | 5.40 | 1.70 | 4.03 |
| 使用Gzip进行压缩 | 2.49 | 1.25 | 1.78 |
| 使用Brotli进行压缩 | 3.00 | 1.30 | 2.00 |
吞吐率
1 | Benchmark Mode Cnt Score Error Units |
线上性能测试
| 操作 | CPU平均使用率 | memcached QPS |
|---|---|---|
| 无压缩读 | 431% | 15.35k |
| zstd解压读 | 745% | 17.42k |
| zstd带字典的解压读 | 695% | 20.13k |
结果分析
- zstd使用训练过的字典在压缩比和吞吐率变现都十分出色
- 字典面对与训练集不同的输入发生了退化现象
- 使用压缩后,单个对象体积变小也因此CPU等io的时间缩短。所以反而提高了qps
总结
所以本文写到这里,可以得出结论只有一个,选择一个文本压缩算法最有效的方式是实验,不要轻人别人的测试结果。只能通过实验,才能得出一个更为有效的算法以及参数的选择。
另外,在为实际生产环境选择开源项目时还有其他因素需要考虑。比如在笔者测试的过程中,不同压缩算法对于语言的支持也不相同。比如zstd就比较好,第三方的java binding库更新及时,对原生支持较好,封装的api注释清晰方便理解。而反观brotli,官方随提供了Java binding库,但只提供了解压,并未提供解压。性能测试所使用的jbrotli库已经数年未更新,且需要开发人员自己编译安装JNI库。

